
🔮El futuro de Data Engineering | Data Engineering Notes #6
Final de la Temporada #1 de Data Engineering Notes

Este el final de la Temporada #1 de Data Engineering Notes.
En las últimas semanas hemos recorrido juntos la historia y los fundamentos de Data Engineering. Durante este camino exploramos:
La historia del rol del Data Engineer y cómo ha evolucionado (Nota #1)
Los fundamentos de Data Warehouses y modelado dimensional (Nota #2)
Los fundamentos de los Data Lakes, Lakehouses y Open Table formats (Nota #3)
ETL vs ELT, Batch vs Streaming y arquitectura de datos (Nota #4)
Cómo construir una plataforma de datos y buenas prácticas—determinismo, idempotencia e inmutabilidad (Nota #5).
Hoy, en la entrega final de esta temporada, es el turno de hablar del futuro de Data Engineering en un mundo “post-LLMs.”
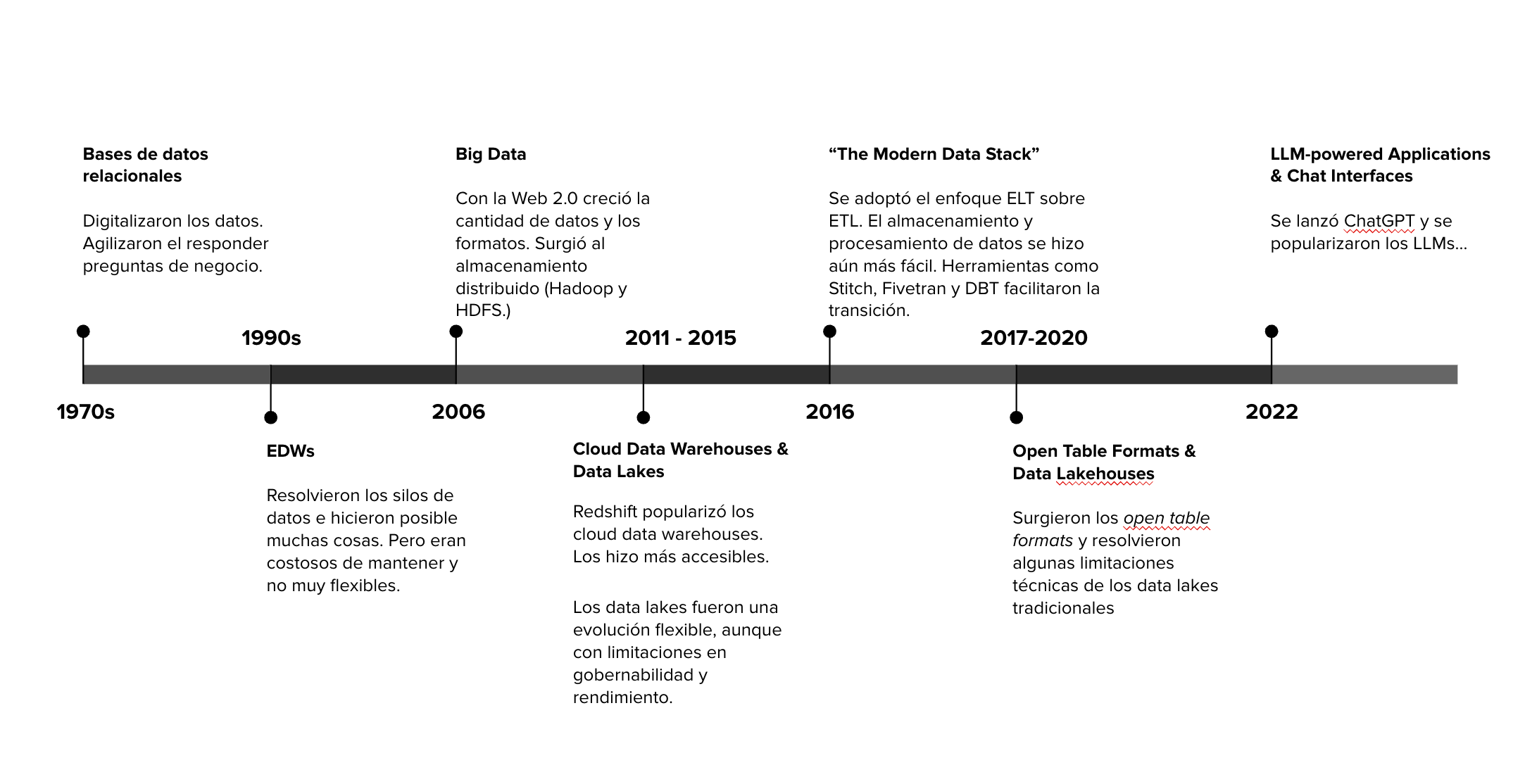
1. Revisitando la Historia de Data Engineering
Data Engineering ha atravesado “cinco eras:”
Era #1: EDWs (Enterprise Data Warehouses) (1990s)
Era #2: Big Data (2006)
Era #3: Cloud Data Warehouses & Data Lakes (2011-2015)
Era #4: The Modern Data Stack (2016)
Era #5: Open Table Formats & Data Lakehouses (2017-2020)
Y en 2022, con la popularización de los LLMs, comenzó lo que podríamos llamar la sexta era del Data Engineering: El surgimiento de los LLMs y el nacimiento de los AI-driven data engineering pipelines.
2. ¿De qué se trata esta nueva era?
Mientras preparaba estas notas me encontré con una frase de Nuno Campos (Founding Engineer en LangChain) que me ayudó a darle forma a lo que estaba intuyendo:
“Los LLMs nos desbloquearon la habilidad de hacer un buen uso de los datos no estructurados…”
Fuente: The Future of Data Engineering in the Agent Era (Minuto: 24:49)
Ahí fue cuando todo tuvo sentido para mí.
Podríamos llamar a esta nueva etapa la era de la multimodalidad.
Data Engineering ya no se limita a datos tabulares y bases de datos SQL.
Hoy también debemos lidiar con PDFs, imágenes, audio y texto libre—que, de hecho, la mayor parte de la información disponible en el mundo es justamente no estructurada.
Hasta 2022, la gran mayoría de pipelines que construíamos estaban diseñados para datos estructurados.
El trabajo con datos no estructurados se hacía, sí, pero siempre fue más complejo y menos accesible. Su verdadero potencial estaba limitado por las herramientas de la época.
Y eso es exactamente lo que cambió y propulsó a esta sexta era de Data Engineering:
Los LLMs no solo abrieron nuevos casos de uso, sino que habilitaron escenarios que antes eran demasiado costosos, directamente inviables, o técnicamente demasiado complejos.
Introdujeron un cambio de paradigma: El paradigma de la multimodalidad
3. Un nuevo paradigma
Quizá estoy exagerando, pero para mí esto se parece mucho a lo que pasó con la Teoría General de la Relatividad de Einstein.
Dicha teoría nunca hubiera podido ser formulada sin apoyarse en la geometría de Riemann, un tipo de geometría no euclidiana.
La introducción de la geometría no euclidiana representó un cambio de paradigma fundamental en las matemáticas: abrió puertas que antes simplemente no existían.
Así mismo sucede con Data Engineering y los LLMs: habilitaron casos de uso que nunca hubiéramos considerado posibles (o al menos no de manera sencilla).
En este nuevo contexto, los LLMs son esa nueva geometría:
Ahora podemos acelerar el desarrollo con generación de código, e incluso imaginar pipelines de datos creados completamente por agentes y LLMs—probablemente, esto es “the holy grail,” pero no creo que estemos lejos de ahí.
Ahora podemos imaginar hablar con nuestros data warehouses en lenguaje natural gracias a protocolos como MCP y funcionalidades como text-to-SQL. Aún hay muchos retos por resolver, pero ya vemos los primeros pasos: desde 2024 Snowflake permite hacer esto con Snowflake Cortex AI.
Hoy, todavía estamos explorando y, en muchos casos, “hipotetizando” sobre cómo aprovechar estas nuevas capacidades—por ejemplo, en este artículo Preset presenta 10 casos de uso que ellos ven posibles con las nuevas capacidades de hoy.
Si bien aún todo esto está en desarrollo y hay mucho ruido, lo que está claro es que estamos frente a una nueva forma de hacer Data Engineering.
4. Tres perspectivas sobre el futuro de Data Engineering
La velocidad de cambio en estos temas es muy alta en estos momentos.
Muchas de las tecnologías y prácticas que hoy estamos probando necesitan tiempo para estabilizarse antes de que podamos ver con claridad cuál será el camino más dominante.
Sin embargo, si tuviera que resumir cómo veo el presente y el futuro de Data Engineering, lo haría en tres perspectivas:
Perspectiva #1: La forma tradicional se queda (por ahora)
Mientras haya que extraer, transformar y cargar datos, seguirá habiendo Data Engineering.
Mi creencia es que los Data Warehouses, Data Lakes y Lakehouses seguirán siendo la base durante un buen tiempo.
Lo que cambiará será cómo interactuamos con ellos:
Más Text-to-SQL, para consultar datos sin escribir una línea de SQL—como Snowflake AI Cortex Analyst.
Semantic layers, que abstraen la complejidad de los modelos y proveen metadatos útiles para los LLMs.
Mayores integraciones con MCP (Model Context Protocol), conectando aplicaciones y datos de forma más directa.
Perspectiva #2. La representación de datos no estructurados será clave
Los LLMs son tan buenos como los datos que reciben.
Garbage in = Garbage out.
Esto hace que los data engineers necesitemos aprender más sobre:
Bases de datos vectoriales que son el alma detrás de los RAGs (Retrieval Augmented Generation), el caso de uso más común de LLMs hasta estos momentos.
Knowledge graphs. Parece ser que los GraphRAGs tienen mejor rendimiento sobre los RAGs tradicionales debido a la riqueza de metadatos y relaciones que modelan las bases de datos basadas en grafos.
Un buen vídeo hablando knowledge graphs: Philip Rathle, CTO, Neo4J: Why Knowledge Graphs are Necessary for Enterprise AI
Perspectiva #3: Casos de uso near-real-time
La mayoría de los pipelines de Data Engineering todavía son batch, pero los LLMs están empujando escenarios donde la latencia importa.
Un ejemplo: chatbots empresariales que necesitan responder con acceso directo a datos internos en cuestión de segundos.
Esto traerá la necesidad de arquitecturas con:
Acceso optimizado a datos.
Pre-procesamiento en tiempo real.
Calidad de datos garantizada incluso en pipelines rápidos y continuos.
Un buen ejemplo de esto es un Chatbot desarrollado por Uber para atender preguntas de soporte.
En la siguiente se presenta la arquitectura. Si quieres leer el artículo completo, te recomiendo hacerlo aquí: Genie: Uber’s Gen AI On-Call Copilot.

5. ¿Qué aprender?
Si algo me queda claro después de esta breve investigación es que el rol del data engineer no desaparece: se transforma.
De cara a esta “sexta era” de Data Engineering, hay tres habilidades que considero especialmente relevantes:
Aprender los fundamentos. Sería un error pensar que no es necesario aprender data engineering clásico. Almacenamiento de datos (DWs, DLs, DLHs), modelado de datos, calidad y diseño de arquitecturas, etc… Todo eso sigue siendo la base. Los LLMs no reemplazan la arquitectura, ni los data engineering, ni la lógica de negocio: simplemente son un potenciador.
Manejo y almacenamiento de datos no estructurados. La mayor parte de data engineering estaba basada en datos tabulares. Ahora, tenemos una explosión de casos de uso basados en datos no estructurados. Esto significa aprender a trabajar con diferentes bases de datos, la más relevantes actualmente, vectoriales y basadas en grafos.
Procesamiento de datos “near-real-time.” La latencia empieza a importar cada vez más. Casos de uso como los chatbots o asistentes de soporte requieren arquitecturas que permitan acceso optimizado, pre-procesamiento inmediato y pipelines confiables con latencias bajas.
🚀 Segunda cohorte del Data Engineering Bootcamp
Si has venido siguiendo mi serie de Data Engineering Notes, sabrás que durante Julio y Agosto tuvo lugar la primera cohorte de mi bootcamp de Data Engineering.
Ahora se viene la segunda cohorte.
Si quieres dar el salto al mundo de la Ingeniería de Datos, pero sientes que todavía no tienes la confianza ni los fundamentos técnicos para hacerlo, este bootcamp es para ti.
📅 Fechas: 4 de Octubre al 8 de Noviembre de 2025
🚨 Cupos limitados: 16 participantes
Inscripciones abiertas hasta el 2 de Septiembre de 2025.
Fin de la primera temporada
Con esta entrada cerramos la primera temporada de Data Engineering Notes.
Este proyecto comenzó como una forma de ordenar mis notas de preparación para la primera cohorte del bootcamp de Data Engineering… y terminó convirtiéndose en una serie que me permitió compartir aprendizajes, historias y preguntas abiertas con todos ustedes.
Acá todas las notas de esta primera temporada:
La historia del rol del Data Engineer y cómo ha evolucionado (Nota #1)
Los fundamentos de Data Warehouses y modelado dimensional (Nota #2)
Los fundamentos de los Data Lakes, Lakehouses y Open Table formats (Nota #3)
ETL vs ELT, Batch vs Streaming y arquitectura de datos (Nota #4)
Cómo construir una plataforma de datos y buenas prácticas—determinismo, idempotencia e inmutabilidad (Nota #5).
Gracias infinitas a todos.
Hasta la próxima!